Token Wars
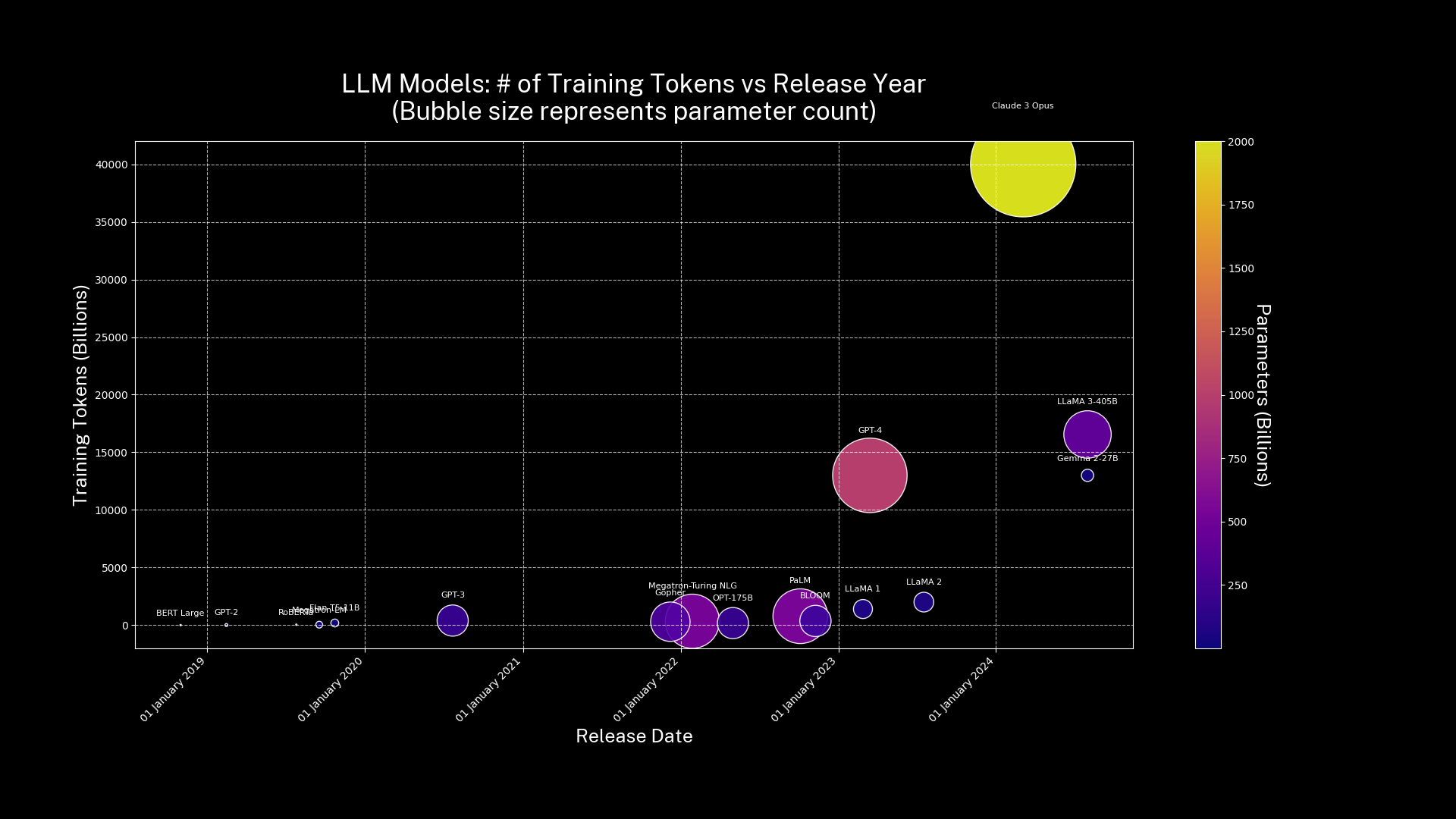
PhD Researcher Kathy Reid (she/her) is an AI Voice researcher investigating speech technologies with a focus on the data that goes into these models. Kathy asks critical questions about these technologies, the people, and the voices they serve. Kathy’s motivation both personally and professionally is the value that knowledge is power and knowledge shared is empowerment. These underlying understandings are core to Kathy’s PhD work and also her keynote talk Token Wars. With these values and a highly open-source background it may come as a surprise to you that Kathy questions if everything should be open not just to anyone but to anything. The continuous scraping and pollution of the internet by AI companies looking to train their latest models is deeply challenging to the ‘everything open’ approach. Kathy and her research ask a lot of great questions about technology and power - who benefits from technologies and what are the costs? These cybernetics questions about unintended consequences underpin Kathy’s Token Wars, a talk that dives into the current technical, legal, and political, resource conflict surrounding AI training ‘tokens’ or data. Kathy’s talk, as many great talks do, comes in three parts: Part 1: Kathy gives us an accessible overview of tokens and transformers, the technologies that together build large language models like ChatGPT and Claude Part 2: Kathy unpacks the value of tokens, why they mean so much to AI companies, and what it means for these tokens to become a scarce resource. Here, Kathy also dives into the actions and intentions of the key actors in these token wars, as well as the damage they are causing. Part 3: Kathy considers tokens and data as a form of treasure or capital – and asks how we might protect and safeguard this treasure. Kathy also speculates on the future of tokens and future protection strategies. The Token Wars: why not all our content should be open Token Wars was first delivered by Kathy Reid at Everything Open and the Melbourne Machine Learning and AI meetup. This version of Token Wars was delivered on Ngunnawal and Ngambri Country here at the Australian National University’s School of Cybernetics. Current LLMs are trained on nearly all the publicly available data in the world – and globally we’re running out of new human-generated ‘tokens’ to train newer and better models on. Kathy holds that we’ve passed a point in history she terms “Peak Token” - where we have the highest availability of human-generated tokens. As LLMs and synthetics data proliferate, the open web is becoming increasingly filled with low-quality “AI slop”, ushering in the “slopocene” - where rich, diverse, human-generated data is rarer and more valuable. LLM Models: Number of training tokens and parameter size by date. 2025-04-13 https://github.com/KathyReid/token-wars-dataviz. Visit Kathy’s blog for her recent thoughts on the speculative OpenAI hardware device that may come about as a result of these Token Wars and find out more about Kathy’s research on our PhD Spotlight from earlier this year.